Hello.
My name is Kevin Burns and this is my website.
Recent Blog Posts
The Hidden Cost of Info Logging
What is the performance cost of ignored Debug and Info logs in production?
The L in SOLID
A case study illustrating the consequences of Liskov Substitution Principle violation
Top Skills
Software Architecture
Attribute Driven Design, Latency, Throughput, Efficiency, Scalability, Extensibility, Maintainability, Visibility, Documentation
Agile Planning
Scrum, Kanban, Planning, Retrospectives, Safety, Honesty, Ownership, Delegated Authority, Leadership, Process Measurement, Process Design, Automation
Information Architecture
The study and practice of information organization.
Recent Roles
CrunchyrollApplication Architect
Hired as a Senior Secure Application Engineer and skip promoted past staff engineer to Application Architect after 18 months. Read More >
Recent Projects
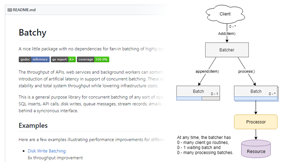
Batchy
Simple fan-in batching for optimization of highly concurrent workloads.
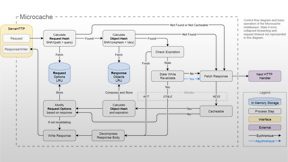
Microcache
A non-standard HTTP cache implemented as Go middleware.
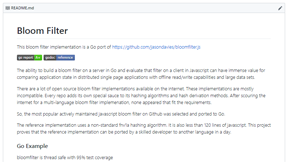
Bloomfilter
A bloomfilter written in javascript ported to Go for portability.